Hadoop Archive Files In HDFS
Hadoop Archive
• HDFS Shares small files in efficiently, since each file is stored in a block and block meta data is held in memory by the Name Node.
• Thus, a large number of small files can take a lot of memory on the Name Node for example, 1 MB file is stored with a block size of 128 MB uses 1.MB of disk space not 128 MB.
• Hadoop Archives or HAR files, are a file archiving facility that packs files into HDFS blocks more efficiently, there by reducing Name Node memory usage while still allowing transparent access to files,
• Hadoop Archives can be used as input to map reduce.
Using Hadoop Archives:
→ A Hadoop Archives is created from a collection of files using the archivetool, which runs a map reduce job to process the input files in parallel and to run it, you need a map reduce cluster running to use it.
→ Here are some files in Hadoop Distributed File System (HDFS) that you would like to archieve:
%hadoop fs-lsr/my/files.
→ Now we can run the archivecommand:
% hadoop archive–archivename files.har/my/files/my
HRA files always have a .har extension which is mandatory
→ Here we are achieving only one source here, the files in /my/files in HDFS, but the tool accepts multiple source trees and the final argument is the out put directory for the HAR file
→ The archive created for the above command is
%hadoop fs-ls/my
Found 2 items
Drwr-x-x – tom super group 0 2009-04-09 19:13/my/files
Drwr-x-x – tom super group 0 2009-04-09 19:13/my/files hor
→ In HDFS, Blocks are replicated across multiple machines known as data nodes and default replication is three – fold i.e. each block exists on three different machines
→ A master node called the Name Node keeps tracker of which blocks make up a file and where those blocks are located known as the meta data.
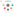
Example:
• Name Node holds meta data for the two files. Are Foo.txt and Bar .txt Name Node
Foo.txt:blk-001, blk-002, blk-003Foo.txt:blk-004, blk-005
• Data nodes hold the actual blacks
• Each block will be 64MB OR 128MB in size
• Each block is replicated three times on the cluster
.png&w=16&q=75)
• The Name Node daemon must be running at all times and if the Name Node stops, the cluster becomes in accessible and then the system administrator will take care to ensure that the Name Node hard ware is reliable
• The Name Node holds all of its meta data in RAM for fast access and it keeps a record of changes on disk for crash recovery.
• A separate daemon known as the secondary Name Node takes care of some housekeeping tasks for the Name Node and be careful that the secondary Name Node is not a back up Name Node.
Note:
→ Although files are split into 64MB OR 12MB blocks, if a file is smaller than this the full 64MB / 128MB will not be used.
→ Blocks are stored as standard files on the data node, in a set of directories specified in hadoop configuration files and this will be set by the system administration
→ Without the meta data on the Name Node, there is no way to access the files in the HDFS Cluster
When a client application wants to read a file:
a) It communicates with the Name Node to determine which blocks make up the file and which data nodes those blocks reside on.
b) It then communicates directly with the data nodes to read the data.
c) The Name Node will not be a bottle neck.

Frequently asked Hadoop Interview Questions
List of Big Data Courses:
| Hadoop Adminstartion | MapReduce |
| Big Data On AWS | Informatica Big Data Integration |
| Bigdata Greenplum DBA | Informatica Big Data Edition |
| Hadoop Hive | Impala |
| Hadoop Testing | Apache Mahout |
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Hadoop Training | Apr 22 to May 07 | View Details |
| Hadoop Training | Apr 26 to May 11 | View Details |
| Hadoop Training | Apr 29 to May 14 | View Details |
| Hadoop Training | May 03 to May 18 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.















- Apache Hadoop YARN
- Apache Pig Interview Questions
- Benefits Of Cloudera Hadoop Certification
- Hadoop Administration Interview Questions
- Hadoop Ecosystem
- Hadoop HDFS Commands with Examples
- Hadoop Interview Questions
- Hadoop Jobs Salary Trends in the USA
- Mapreduce in Bigdata
- Big Data Hadoop Testing Interview Questions
- Hadoop Tutorial
- An Overview Of Hadoop Hive
- Hadoop’s Pig Data Types and Syntax
- Hadoop Apache Pig Execution Types
- Controlling Hadoop Jobs Using Oozie
- HBase Vs RDBMS
- HDFS Architecture, Features & How To Access HDFS - Hadoop
- Hadoop Data Types with Examples
- Hadoop – How To Build A Work Flow Using Oozie
- How to Insert Data into Tables from Queries in Hadoop
- Hadoop Hive UDF
- INTRODUCTION TO APACHE PIG – HADOOP
- Introduction to HBase for Hadoop
- What is HDFS?
- Hadoop Job Operations
- Hadoop Mapreduce Architecture Overview
- Apache Sqoop Tutorial
- What Is Hadoop Hive Query Language
- Hadoop Installation and Configuration
- How Much Java Knowledge Is Required To Learn Hadoop?
- Prerequisites for Learning Hadoop
- Top 10 Reasons to Learn Hadoop
- How to Switch Your Career From Java To Hadoop
- Leading Hadoop Vendors in BigData
- What is Apache Pig
- Why Network Security Needs to Have Big Data Analytics?
- Sqoop Interview Questions
- Cloudera vs Hortonworks
- Difference between Pig and Hive
- Big Data Hadoop Interview Questions
- Hive Projects and Use Cases